


| Contents | |
| 1. | Overview |
| 2. | Richardson-Lucy and other Fourier-Based Algorithms |
| 2.2 | Richardson-Lucy and the UltraDeep Survey |
| 3. | CLEAN |
| 4. | For additional reading, try Appendix B of my thesis. |
|
|
|
|
| Truth Image | Pipeline Coadder | R-L 20 iterations |

|
| Lucy-Hook Coaddition of 8 12um Frames |
|

|
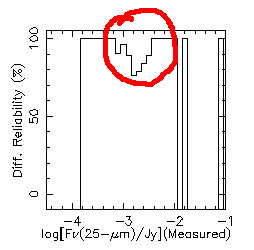
| The notch in differential reliability... | And it's cause - artifacting around bright point sources. |
|
|
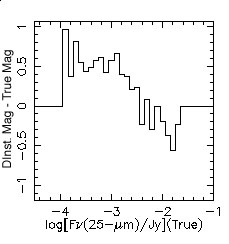
Difference between instrumental and true magnitude. Because the shape of the PSF changes as a function of source brightness, DAOPHOT under/overestimates the source brightness. |

|
|
Red sources are true matches detected in the raw coadd. The green circles are new matches made after the original positions were scrambled. In theory, no new matches should have occurred - these six are the result of randomly matching sources meeting our position and brightness constraints. |
|
|
 |
|
| Pipeline Coadder | CLEANed Image | Truth Image |